易翻译把“语言”这件事变成了社群里的基础设施:通过自动识别与翻译、角色分工和分区管理、结合人工审核与本地化运营,把多语言交流变成可控、可衡量的日常工作,从而既保证沟通效率,又维护社群秩序与文化敏感性。

先把问题讲清楚:为什么多语言社群需要特殊管理
想象一下你在一个派对里,大家说着不同的方言和外语,信息像气球四处飘——热闹是热闹,但容易误会、信息重复、有人被孤立。多语言社群就是这种情形的线上版:语言差异会放大认知偏差、延迟反馈、内容监管难度以及本地化需求。管理得好,社群多元活跃;管理不好,信息混乱,用户体验变差,甚至引发文化冲突或法律风险。
核心难点一览
- 理解与响应延时:不同语言用户期待及时回应,但翻译需要时间或成本。
- 一致性问题:规则、公告、活动信息在不同语言之间常常不一致或语义错位。
- 内容审核难:自动翻译可能误判敏感词,人工审核又耗资源。
- 本地化差异:文化敏感点、节日时间、付费习惯都不一样。
易翻译在多语言社群管理中的定位与作用
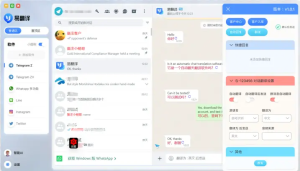
把易翻译看成“语言中枢 + 操作工具包”。它既做翻译,也做流程支撑:自动识别语言、实时互译、影像识词、双语对话,再配合社群管理策略,就能把语言障碍从核心瓶颈变成可配置的模块。
几个直观功能与它们解决的问题
- 自动语言识别 —— 新用户发言立刻识别语言,自动归类并触发对应模板或管理员。
- 实时互译(文本/语音) —— 聊天、语音会议中即时翻译,降低等待和误解。
- 拍照取词 —— 本地图片、截图里的文字也能翻译,便于处理截图型证据或公告。
- 双语对话模式 —— 提供“原文+译文”的并列视图,让双方看到彼此话语的原貌和译文,减少误解。
- 接口与日志 —— 与社群工具(群管理、工单系统)联动,翻译与审查都有痕迹,便于追责与优化。
把功能变成流程:实际可落地的管理模块
工具没有魔法,关键在于把它嵌入人的流程里。下面分块讲,像搭积木一样把体系搭起来。
1. 分区与分组策略(先把人分类)
把社群按语言、主题和地区分区。语言分区便于做自动化策略(比如自动翻译等级、优先审核队列),主题分区便于匹配本地化内容和志愿者。
- 语言分区示例:中文群、英文群、法语群,同时保留跨语交流区(翻译支持)。
- 地域分区示例:东南亚用户组、欧洲用户组,便于时区和文化活动安排。
2. 角色与权限(谁做什么)
明确分工能把“谁翻、谁审、谁处理”变成标准操作。下面是一个常见的角色表:
| 角色 | 职能 | 是否需要语言能力 |
| 群管理员 | 日常管理、规则执行、紧急处理 | 不强制(可支持自动翻译) |
| 语言版主(志愿/兼职) | 本地语言审核、文化敏感性判断、翻译校对 | 必须 |
| 内容审核员 | 复核自动翻译结果、处理争议工单 | 建议多语种或配合翻译工具 |
| 运营/数据分析 | 行为分析、活动本地化、效果评估 | 不限,但需理解多语言指标 |
3. 消息流与翻译优先级(谁都能说话,但谁先听)
不是所有内容都需要同等级别的翻译。把消息按类型分级处理:
- 紧急/安全类(例如涉险、诈骗、违规)——即时人工介入,自动高优先级通知多语版主。
- 公告/活动——先由运营翻译并校对,放出前在所有语言组同步,保留本地化注记。
- 用户日常交流——默认机器翻译+“查看原文”提示,争议时升级人工复核。
4. 内容审核与人工复核流程
把自动化和人工审核结合起来是关键:机器先筛、人工复核。这个流程可以简化为“旗帜——筛查——复核——归档”。
- 自动旗帜:关键词、情绪检测、图像识别。
- 语言匹配:把需要复核的文本推送给相应语言版主。
- 复核结果记录:结果写入工单系统,构成后续训练数据。
如何用易翻译设计日常操作手册(一步步来)
下面给出一套可直接复制的日常操作步骤,适合中大型社区使用。
入群与新手欢迎(Onboarding)
- 新用户进群,易翻译自动识别语言并发送欢迎消息(包含社群规则链接、常见问题)。
- 欢迎消息示例(并列双语):“欢迎来到X社区!请先阅读社群守则(查看原文/English)。若需帮助,回复‘help’或联系版主。”
- 引导加入相应语言分区或主题小组(自动推荐)。
日常发言与自动回复策略
- 默认展现并列视图:原文 + 译文。避免只看译文导致误解。
- 对常见问题设定FAQ自动回复,按语言推送本地化答案。
- 对于敏感词自动触发“此消息将由人工复核”的提示,降低迅速误判的风险。
活动与公告发布流程
活动在一种语言制定后,应按以下流程落地到其他语言:
- 源语言撰稿 → 专人翻译(或易翻译初译) → 语言版主校对 → 统一发布时间(考虑时区) → 发布后监测反馈并采集翻译反馈。
数据与反馈:用数字优化社群运营
把语言管理当作产品来做,关键是指标(KPI)。下面是常用且实操性强的指标:
- 多语言响应时长(按语言分解)
- 自动翻译准确率(人工抽检率)
- 违规/争议消息的平均处理时长
- 用户留存和参与度(按语言、地区)
- 本地化内容转化率(活动报名、付费等)
数据如何推动改进
把审查样本和用户反馈喂回易翻译的翻译评估流程(内部标注集),可以持续提高自动翻译在社群场景下的准确度。运营端要定期召开“语言回顾会”,把各语种的问题、误译案例以及本地化建议汇总,形成可执行的改进清单。
实用模板:规则片段、自动通知、升级工单
给你几段可以直接用的文案片段,轻改即可上线:
- 多语欢迎消息模板:欢迎语(原文) — 易翻译初译 — 版主校对后发布。
- 违规提示(自动):系统检测到可能违规内容,信息将进入人工复核队列,请耐心等待。
- 人工介入升级工单:包含原文、译文、截图、检测理由、优先级与请求操作(删除/警告/禁言)。
风险、合规与文化敏感性
跨语言社群不仅仅是语言问题,还牵涉法律与文化。要把法规、隐私和文化敏感点纳入管理框架:
- 遵守当地数据保护法规(例如对用户语音、图片的存储策略)。
- 对政治、宗教等敏感话题制定更严格的审核策略并明确分级。
- 进行文化适配:节日祝福、禁忌词列表要本地化维护。
常见情形的应对(像在备忘录里写的)
用户抱怨误译导致误会
先道歉、给出并列原文与译文、启动人工复核、把最终纠正结果作为知识库更新,必要时私信解释并提供补偿(如果对用户造成损失)。
紧急安全事件(诈骗或威胁)
立刻把消息标记为高优先级,通知所有相关语言版主并同步英语公告(或源语言公告),同时保留证据并启动封禁流程。
活动翻译不一致引发投诉
把投诉记录为案例,召集源语言作者与语言版主对照修改,更新活动模版,并把“翻译校对”设为必经环节。
让系统学会:用数据训练更好的翻译与规则
一个成熟社群的语言能力来自不断积累的“问题-修正”样本。把人工复核结果、误判样本、用户反馈都结构化,定期用于校准自动翻译模型和关键词库,会使系统越来越适配你的社群语境。
一句实在的话,怎么开始最稳妥
不要一开始全自动化,也不要把所有语言都一刀切。先选3种主要语言:搭建分区、配备至少一名语言版主、把易翻译接入FAQ和公告流程;运行1个月,收集问题与数据,再逐步扩大语言覆盖与自动化程度。这样既稳又可控。
写到这儿,顺手把几个小提示留下:保留“原文可见”是避免误判的良方;把版主培训做成常态;用数据说话,别凭感觉判断。这样一步步下来,语言不再是隔阂,而是让社群更有温度的工具。